The GPT Crawler: A Tool for Custom AI Knowledge Bases
The GPT Crawler is an open-source tool primarily designed to crawl websites and generate structured knowledge files that can be used to create highly customized Large Language Models (LLMs), such as Custom GPTs and Assistants on the OpenAI platform.
It is distinct from general-purpose web scrapers because its output is specifically formatted and optimized to serve as a knowledge base for AI models, injecting proprietary or domain-specific information into a base LLM.
Core Function and Purpose
The primary function of the GPT Crawler is to bridge the gap between unstructured web content and the structured knowledge required by an AI model.
Crawl Websites: The user configures the crawler with one or multiple starting URLs, specific URL matching patterns, and CSS selectors to define which parts of the webpage content are relevant (e.g., scraping only the main article body and skipping sidebars or headers).
Extract & Process Content: Unlike a simple scraper, the GPT Crawler is designed for intelligent content extraction. It often uses a headless browser to render JavaScript content and extracts the text, preserving important metadata. Some versions may also perform semantic parsing and content quality assessment to filter low-value or duplicate text.
Generate Knowledge File: The extracted, cleaned, and processed information is compiled into a single, structured file, typically in JSON format. This file serves as the custom knowledge base.
Create Custom AI: The user then uploads this JSON file to the OpenAI platform (or a similar AI system) to provide the base LLM with the custom, domain-specific information it needs to answer questions about the crawled website content accurately.
Key Features and Advantages
Custom Knowledge Creation: It enables the creation of a tailored knowledge corpus from specific, trusted sources (like a company's documentation or a specialized blog), making the resulting AI model a domain expert.
Intelligent Content Filtering: By allowing configuration of CSS selectors and having built-in filtering, it ensures that the AI is trained on relevant, high-quality text rather than boilerplate or navigation elements.
Scalability and Efficiency: It can be configured to handle large-scale data collection projects efficiently, with features like rate limiting and the ability to process multiple pages/URLs.
Open-Source Nature: The most prominent version, often associated with Builder.io, is an open-source project, allowing developers to freely use, modify, and integrate it into their custom workflows.
Support for Dynamic Content: By often using a headless browser for crawling, it can effectively scrape content rendered by JavaScript, a common challenge for simpler web scrapers.
Use Cases for the GPT Crawler
The primary application is improving the knowledge and performance of generative AI models for a specific context.
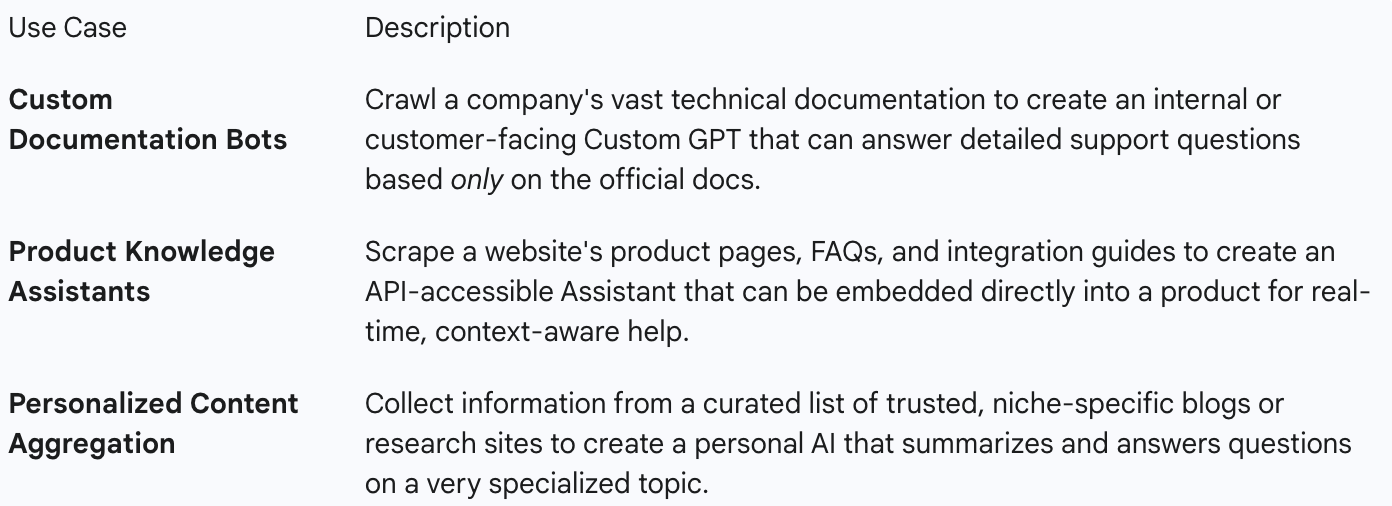
While the primary open-source tool focuses on generating knowledge files for Custom GPTs, it's important to note the existence of GPTBot, which is OpenAI's official, large-scale web crawler used to collect publicly available data for training their general-purpose foundation models like GPT-4.