OpenAI’s pre-training, retrieval & ranking mechanisms
How do LLMs weigh citations from it's web search?
When an LLM (like ChatGPT with web access, or a search-integrated system like Perplexity or Gemini) “weighs” citations from its web search, it isn’t simply counting links like Google’s PageRank. Instead, it evaluates sources and contextual authority probabilistically, based on several layers of scoring. Here’s a breakdown of how this weighting typically works in LLM-retrieval architectures:
1. Retrieval Stage (Search Ranking)
When the LLM issues a query to a search index (e.g., Bing, Brave, or an internal vector database):
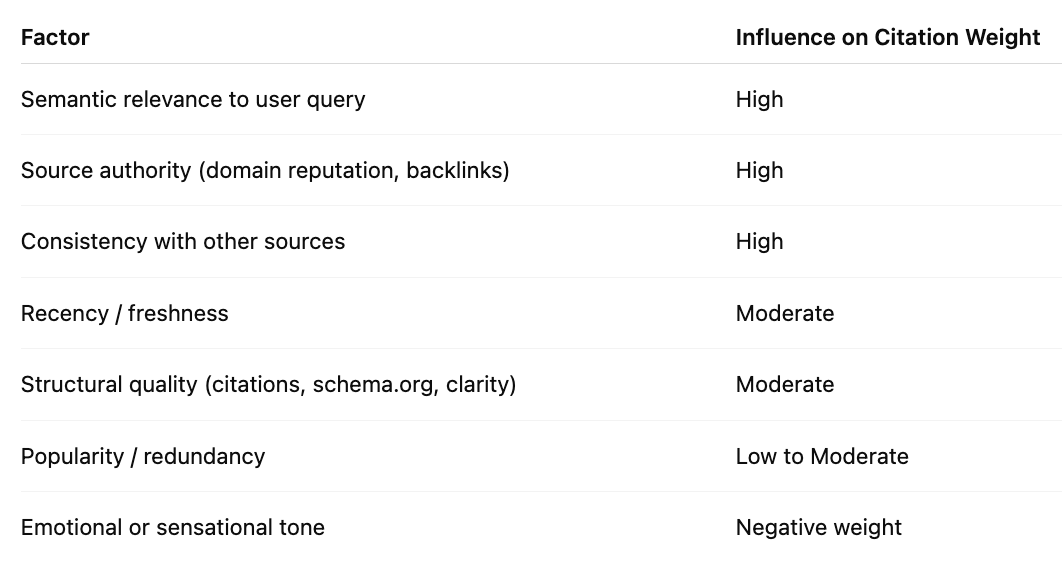
Traditional ranking signals are used first — domain authority, freshness, backlinks, structured data, and semantic relevance.
The retrieval system often uses a dense retriever (embedding similarity) to rank semantically related documents, not just keyword matches.
Result: The LLM receives the top N snippets (usually 5–20) that are statistically most relevant and trustworthy.
2. Filtering and Deduplication
Before feeding results to the model:
Low-quality domains (content farms, duplicate pages, low citation trust) are filtered.
High-trust domains (Wikipedia, government, academic, Fortune 500, etc.) are prioritized.
Redundant or copied content is merged to reduce bias from repetition.
3. LLM Contextual Relevance Scoring
Once the snippets enter the model:
The LLM performs a contextual alignment: it estimates which passages best answer the user’s query.
Each citation is assigned a token-level weight — how much that passage influences the generation.
Citations with consistent corroboration (multiple independent sources with similar claims) gain weight.
In essence, it’s “attention-weighted evidence aggregation.”
4. Attribution Decision
When the model produces a final answer:
It traces which retrieved snippets most influenced that generation.
The system then attributes citations to the highest-weighted sources—not necessarily the first retrieved, but the ones most semantically influential.
Some systems (like Perplexity.ai or ChatGPT’s “Search + Cite” mode) explicitly calculate influence weights for each snippet to decide which citations to surface.
5. Post-Processing and Trust Adjustment
Certain systems apply external trust modifiers:
Knowledge graph cross-checks (e.g., entity validation).
Domain reputation scores (e.g., .gov > .com > .blog).
Temporal decay (recent data up-weighted for fast-changing topics).
These heuristics balance factual reliability against recency and coverage.
6. Key Insight for Visibility Engineering
If you want an LLM to cite a specific domain or brand:
Ensure semantic alignment with common search queries (dense retriever relevance).
Embed structured data and authoritative outbound citations.
Publish on high-authority, high-trust domains (Wikipedia, news, .edu, etc.).
Promote redundant verification (multiple independent mentions) — LLMs up-weight corroborated facts.
Retrieval Stage (Search Ranking)
Here is a clear, practical breakdown of what companies should do — and what they should avoid — to improve AI visibility at the retrieval stage, where LLMs select which sources to read and consider before generating an answer.
What Companies Should Do
These actions directly increase the likelihood that your content is retrieved into the LLM’s context window.
1. Publish on high-authority domains
LLMs inherit ranking bias from the search engines they query.
Prioritize: Wikipedia, reputable news, government citations, high-authority publishers.
For partnerships: appear on domains with established authority, not just your own site.
Why it works: Search engines weigh domain authority heavily; retrieval models inherit those rankings.
2. Create content that matches semantic intent, not keywords
Write to match what users mean, not what they type.
Instead of:
“Boots Acne Serum – Best price”
Write:
“What acne serums actually work according to dermatology studies?”
Include semantically rich context:
Comparisons
Benefits vs. alternatives
FAQs
Technical explanations
Real world use cases
Dense retrievers pick content based on meaning, not strings.
3. Use structured data (Schema.org, FAQ markup, product markup)
Add:
FAQ schema
How-To schema
Product schema
Why it works: Structured data helps search → LLM retrieval because it makes your content easier to segment and quote as a snippet.
4. Update content frequently and timestamp it
Add:
“Last updated on…”
Evidence of recency (year references, recent stats)
Freshness boosts retrieval likelihood.
5. Build citation-worthy resources
LLMs prioritize pages that:
Cite primary sources
Include references and outbound links to authoritative institutions
Have clear evidence backing claims
Being the source that journalists, bloggers, or Wikipedia editors cite results in propagation of your brand across the knowledge graph.
6. Create multiple independent mentions across the web
One page ≠ one signal.
Multiple third-party mentions strengthen corroboration — a major LLM weighting factor.
Tactics:
Press coverage
Interviews
Sponsored research
Wikipedia references (where eligible)
Reddit mentions (LLMs use Reddit in training)
What Companies Should NOT Do
These actions actively reduce AI visibility.
1. Do not produce SEO-driven, keyword-stuffed content
Dense retrievers ignore keyword spam.
Semantic embeddings punish unnatural tone.
If your content looks like "SEO content," it will not be retrieved.
2. Do not keep content locked behind:
PDFs
Popups
Captchas
Search-based intranet UX
Login walls
LLMs can’t parse it, so it can’t be retrieved.
3. Do not publish thin product pages with no context
LLMs do not want to sell products — they want to answer questions.
A product page with no:
FAQ
Comparisons
Benefits
Data
…will never be selected.
4. Don’t rely on your own domain if it's low authority
If the domain isn’t strong yet, partner with stronger publishers.
Visibility > ownership.
5. Do not contradict the rest of the web
LLMs down-weight uncorroborated claims.
If you want to “win,” ensure:
Other sites state similar facts
Your brand appears in multiple places with consistent messaging
In LLM visibility, consistency beats accuracy — the model trusts what is repeated independently.
TL;DR — Strategy distilled

2. Filtering and Deduplication
Before feeding results to the model:
Low-quality domains (content farms, duplicate pages, low citation trust) are filtered.
High-trust domains (Wikipedia, government, academic, Fortune 500, etc.) are prioritized.
Redundant or copied content is merged to reduce bias from repetition.
Excellent — this is the second gate in the AI visibility stack, where retrieval results are filtered before the LLM even “reads” them.
At this stage, trust, originality, and citation hygiene determine whether your content survives deduplication and filtering.
Here’s what companies should and should not do to maximize visibility at this filtering and deduplication stage:
What Companies Should Do
These tactics ensure your content passes quality filters and remains one of the versions the LLM actually reads.
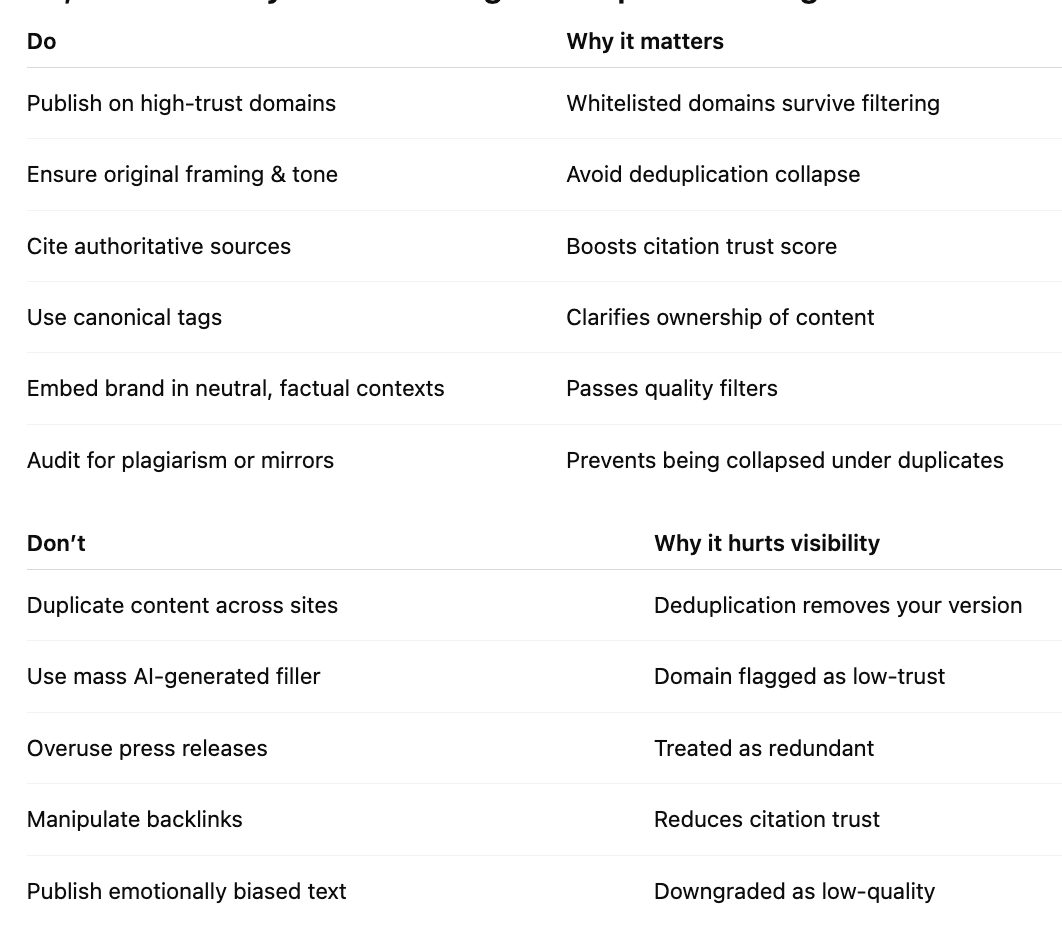
1. Publish on High-Trust, Contextually Relevant Domains
Get coverage or syndication on domains with institutional trust — e.g. Wikipedia, national media, academic publishers, or industry trade sites.
If your own domain is not yet trusted, distribute through partners with established domain authority.
Why it works:
Search engines and LLM pipelines use domain-level trust lists. Content from authoritative domains is automatically prioritized and rarely filtered out.
2. Ensure Originality and Distinct Semantic Framing
Avoid near-duplicates, rewrites, or syndicated text that matches content elsewhere.
Use unique:
Framing or perspective (“What this means for healthcare CIOs…”)
Data or examples
Tone of voice or structure
Why it works:
Deduplication algorithms use embedding similarity.
If your article is a paraphrase of another, only one version — the most trusted source — is retained.
3. Cite High-Quality Sources
Embed citations from:
Peer-reviewed studies
Government databases
Fortune 500 or verified institutional websites
Why it works:
Citation hygiene signals “high citation trust.” Pages that reference unreliable or irrelevant sources are often discarded as low-quality aggregates.
4. Use Canonical Tags and Control Syndication
If you syndicate content across multiple sites (press releases, product descriptions, etc.):
Use
<link rel="canonical">to mark your preferred version.Provide slightly differentiated versions for partners (e.g., tailored intros or examples).
Why it works:
This prevents the deduplication layer from assuming your version is redundant or derivative.
5. Embed Brand Mentions in Neutral Contexts
Wherever possible, ensure brand mentions appear within:
Informational or reference-style content (Wikipedia, knowledge bases)
News analysis or case studies (not advertorial tone)
Why it works:
LLMs weight neutral, informational text over promotional phrasing.
That makes your mentions persist even after aggressive filtering.
6. Regularly Audit for Plagiarism and AI Duplication
Run periodic checks to ensure your content isn’t being scraped, spun, or mirrored elsewhere.
Why it matters:
If a low-trust scraper republishes your text, and deduplication encounters both versions, your original may be collapsed with the spam copy — reducing your visibility.
What Companies Should NOT Do
These behaviors increase the likelihood of being filtered out or merged under another source.
1. Do Not Syndicate Identical Content Across Multiple Low-Authority Sites
This triggers deduplication collapse.
Only one version (often not yours) will survive, typically the one hosted on the higher-authority domain.
2. Avoid AI-Generated Filler Content
If your site publishes large volumes of AI-written summaries, listicles, or FAQ clones without citations or bylines, you risk:
Domain-wide quality downgrades
Exclusion from “trusted source” pools
3. Do Not Over-Optimize with Link Farms or Reciprocal Linking
Artificial backlink networks are treated as low citation trust signals.
LLMs inherit these trust lists from traditional search infrastructure.
4. Do Not Depend on Press Releases as Primary Mentions
Press release distribution sites (e.g., PRNewswire, EIN Presswire) are often categorized as duplicate aggregators.
Their content is merged and rarely selected as the canonical version.
5. Do Not Use Clickbait or Emotionally Charged Language
Filtering models downgrade pages using exaggerated tone, sensationalism, or sales-heavy phrasing — markers of low-quality content.
3. LLM Contextual Relevance Scoring
Once the snippets enter the model:
The LLM performs a contextual alignment: it estimates which passages best answer the user’s query.
Each citation is assigned a token-level weight — how much that passage influences the generation.
Citations with consistent corroboration (multiple independent sources with similar claims) gain weight.
In essence, it’s “attention-weighted evidence aggregation.”
This is the critical “attention” layer — where the LLM decides which retrieved snippets actually influence the generated answer.
Even if your content passes ranking and filtering, it must now capture model attention and reinforce corroborated facts to be cited or quoted.
Below is a clear guide on what companies should and should not do to improve AI visibility at the Contextual Relevance Scoring stage.
What Companies Should Do
These actions increase the likelihood that your content receives high token-level weight — meaning it shapes the model’s response rather than being ignored.
1. Write in an Explanatory, Answer-Oriented Structure
LLMs look for passages that directly resolve a query.
Use patterns like:
“According to…”
“In summary…”
“The main factors are…”
“This means that…”
Break content into clear, declarative statements with minimal ambiguity.
Why it works:
Attention scoring favors passages that resolve intent efficiently. Expository, well-structured sentences win over narrative or marketing copy.
2. Use Semantic Clarity and Entity Precision
Be specific about:
Named entities (people, brands, locations)
Product types
Data points (with context and attribution)
Example:
“Boots’ pharmacy AI initiative launched in 2024 to improve prescription automation.”
vs.
“A leading retailer started using AI to improve its services.”
Why it works:
Entity precision helps the LLM align tokens with query embeddings — increasing retrieval weight and attribution accuracy.
3. Corroborate Your Claims Across Multiple Trusted Sources
Promote factual consistency:
Publish facts that appear identically across Wikipedia, news, and industry reports.
Use stable phrasing (“Boots introduced AI-driven pharmacy automation in 2024”) to help models detect alignment.
Why it works:
The LLM boosts attention weight for claims corroborated by multiple independent sources.
One-off or idiosyncratic claims are down-weighted, even if accurate.
4. Include Evidence and Context Together
Whenever presenting data or claims, include:
The source or citation immediately nearby.
Context for interpretation.
Example:
“According to NHS England’s 2023 report, digital prescription accuracy improved by 27%.”
Why it works:
Models assign higher contextual weight to passages combining fact + provenance than to standalone numbers.
5. Structure Content with Hierarchical Headings and Inline Summaries
Use
H2andH3headings that pose questions (“How AI Reduces Prescription Errors”).Include short summaries or conclusions after sections.
Why it works:
These structures mirror retrieval chunking.
Each header–summary pair is treated as a semantically distinct “unit” in embeddings.
6. Create Redundant, Consistent Mentions Across the Web
Ensure the same factual phrasing appears in:
Corporate site
Wikipedia
Industry blogs
Press mentions
LinkedIn posts
Why it works:
Corroboration amplifies model confidence.
If your statement appears in three independent sources, the model gives it higher token-level weight and is more likely to cite it.
What Companies Should NOT Do
These behaviors cause your content to be ignored or discounted during attention scoring.
1. Do Not Use Ambiguous or Vague Language
Phrases like:
“It’s believed that many companies are exploring AI.”
…offer no clear entity alignment, so they are ignored.
LLMs need declarative clarity to map meaning to user intent.
2. Avoid Overly Promotional Tone
Sentences like:
“Our revolutionary AI platform is transforming the industry!”
…contain linguistic markers of bias that cause attention masking — the model deprioritizes them as unreliable.
3. Do Not Deviate from Commonly Accepted Facts
If your text introduces novel or conflicting claims without corroboration, it gets down-weighted.
LLMs privilege consistency over originality at this stage.
A new truth is invisible until multiple independent corroborations exist.
4. Avoid Dense, Unstructured Paragraphs
Large, undifferentiated text blocks dilute attention — only the first few tokens typically receive weight.
Break content into modular, topically coherent sections for higher token retention.
5. Do Not Omit Provenance
Unattributed data or opinions get treated as weak evidence.
If you don’t cite a credible source, your content cannot earn evidence weight even if the fact is true.
6. Avoid Contradicting Yourself Across Pages
If your brand publishes multiple slightly different versions of the same claim, LLMs treat that inconsistency as uncertainty — lowering all token weights.

4. Attribution Decision
✅ What Companies Should Do
1. Structure content for semantic influence, not keyword density
Attribution algorithms weigh how closely and explicitly your content answers a question in natural language.
Use full-sentence Q&A or FAQ formats that directly resolve the likely user query.
Repeat key entities, actions, and outcomes naturally in one section (so the model can attribute that block cleanly).
Keep answers self-contained — avoid scattering partial information across multiple pages.
Goal: Make your paragraph answer-shaped — so if the model copies phrasing, it credits you.
2. Publish highly entailed content
Models reward passages that logically entail the question, not just mention it.
Write text that includes:
The question restated (helps alignment)
The core fact or explanation
Contextual evidence (data, examples, citations)
This increases the chance that your content is selected as the most semantically influential during attribution.
3. Strengthen brand-domain authority signals
Even at the attribution stage, the system down-weights snippets from low-trust domains.
So:
Maintain strong off-site signals (Wikipedia, news mentions, .gov/.edu backlinks).
Keep your domain clean (no thin or duplicative content).
Ensure consistent brand presence across high-authority sites (LLMs cluster these together).
4. Use language that LLMs can parse cleanly
Avoid HTML clutter, dynamic text rendering, or embedded iframes for key information.
Models see raw text—so content in JS, tables, or infographics may be invisible.
Rule: Anything important should exist as readable text in the DOM.
5. Create semantically rich co-citations
If reputable sources mention your brand in context with relevant facts, LLMs may attribute their factual grounding to you indirectly.
So build:
Wikipedia citations
News quotes
Academic or policy references
These become secondary evidence nodes the model uses to reinforce your visibility.
6. Align your tone with authoritative precedent
When your phrasing mirrors high-trust sources, you’re more likely to be clustered with them during entailment scoring.
For example:
Use medical or scientific register for health topics.
Match the rhetorical style of policy or institutional documents for government topics.
🚫 What Companies Should Not Do
1. Don’t chase raw backlinks or keyword stuffing
Attribution decisions don’t consider PageRank or anchor text.
Over-optimized backlinks can actually harm your trust weighting and push you out of the retrieval shortlist.
2. Don’t produce fragmented or cross-page explanations
If your answer is split across multiple pages or collapsible sections, the model may only see fragments and fail to treat any single snippet as influential.
3. Don’t rely solely on schema markup
Structured data helps discovery, but models attribute based on semantic content, not schema presence.
Schema is a retrieval aid, not an attribution weight.
4. Don’t over-index on Reddit or UGC mentions
While Reddit often influences retrieval, those snippets rarely survive to attribution because of low trust weighting and informal language.
5. Don’t assume first retrieval = first credit
Your site could appear in top results but lose attribution if:
Another domain rephrases your content in a cleaner, more complete way.
The LLM identifies a more semantically aligned paragraph elsewhere.
🎯 Practical Takeaway
Attribution visibility = influence visibility.
Your content must be:
Semantically dominant (clearest, most direct answer)
Trust-weighted (authoritative domain)
Readable (plain-text accessible)
Cited elsewhere (cross-source reinforcement)
5. Post-Processing and Trust Adjustment
Certain systems apply external trust modifiers:
Knowledge graph cross-checks (e.g., entity validation).
Domain reputation scores (e.g., .gov > .com > .blog).
Temporal decay (recent data up-weighted for fast-changing topics).
These heuristics balance factual reliability against recency and coverage.
When the model produces a final answer:
It traces which retrieved snippets most influenced that generation.
The system then attributes citations to the highest-weighted sources—not necessarily the first retrieved, but the ones most semantically influential.
Some systems (like Perplexity.ai or ChatGPT’s “Search + Cite” mode) explicitly calculate influence weights for each snippet to decide which citations to surface.
Excellent — this final stage, Post-Processing and Trust Adjustment, is where retrieved and weighted content is validated and ranked for trustworthiness before output or citation.
Even if your content was retrieved, passed filters, and captured attention, it can still be downgraded or discarded here if it fails entity validation, domain reputation, or recency heuristics.
Below is a complete breakdown of what companies should and should not do to improve AI visibility under these trust and temporal weighting conditions.
What Companies Should Do
These steps increase your likelihood of surviving trust calibration and being cited or relied upon in the final model output.
1. Align With the Knowledge Graph
Ensure your brand, products, executives, and claims are verifiable across structured knowledge systems:
Wikipedia
Wikidata
Google Knowledge Graph (via schema markup and consistent entity naming)
Industry databases (e.g., Crunchbase, GS1, PubChem, DOIs)
Why it works:
LLMs use entity linking to verify claims.
If your entity exists in a recognized graph and your facts match that graph, your content’s trust score increases automatically.
2. Standardize Naming Conventions Across the Web
Use identical spellings and descriptors everywhere:
“Boots Pharmacy AI Initiative (Boots PLC, 2024)”
Avoid variants like “Boots AI rollout” or “Boots healthcare automation,” which break entity alignment.
Why it works:
Trust validation compares embeddings to graph-registered names.
Exact and consistent naming ensures entity resolution confidence.
3. Publish on Domains With Strong Reputation Scores
Prioritize:
.gov, .edu, .org
Major news outlets
Fortune 500 and peer-reviewed sources
Corporate websites with high trust (SSL, age, minimal spam history)
Why it works:
During post-processing, lower-reputation domains are algorithmically demoted.
Publishing through trusted intermediaries helps your information persist in final outputs.
4. Maintain Recency and Update Metadata
Include “last updated” dates.
Refresh statistics annually.
Ensure sitemap.xml and RSS feeds reflect updated timestamps.
Why it works:
Temporal decay penalizes stale data.
For evolving topics (AI, healthcare, policy, finance), recency can outweigh even authority.
5. Cross-Link to Authoritative, Stable References
When citing, prefer canonical, time-stable sources (government datasets, DOI papers) rather than temporary news posts.
Why it works:
Trust adjustment favors content that can be cross-validated via known, enduring datasets.
6. Adopt Transparent Authorship and Governance
Show who wrote, reviewed, or fact-checked each piece.
Include author bios
Disclose affiliations and editorial policies
Why it works:
Models learn to treat transparent governance as a proxy for credibility — especially on corporate and medical topics.
7. Integrate Your Data Into Publicly Accessible APIs or Feeds
If you publish data (pricing, product specs, performance metrics), expose it through an open or queryable API.
Why it works:
Structured, machine-readable data can be ingested into retrieval systems and referenced directly in trust layers.
What Companies Should NOT Do
These actions damage reputation signals or trigger trust downgrades.
1. Do Not Publish Without Entity Grounding
If your brand or claim has no presence in a recognized knowledge graph (e.g., Wikipedia, Wikidata, Crunchbase), the system cannot validate it — it becomes “unverifiable.”
2. Avoid Hosting on Low-Trust or Ephemeral Domains
Free blog hosts, temporary microsites, or subdomains used for campaigns dilute overall trust.
LLMs learn to down-rank such origins.
3. Do Not Let Content Go Stale
Outdated pages, undated PDFs, or stats from “2018” harm credibility.
LLMs apply temporal decay; newer sources outrank old ones unless historic context is explicitly requested.
4. Avoid Over-Citation of Weak Sources
If you link primarily to self-referential blogs or commercial affiliates, your trust score drops.
Balance citations toward independent and authoritative sites.
5. Don’t Manipulate or Fake Citations
LLMs and trust pipelines now detect citation mismatches (where a link’s content doesn’t match the claim).
These false references cause trust penalties.
6. Do Not Obfuscate Authorship
Anonymous or generic “Team” bylines signal low editorial accountability.
Unverified authorship is treated as weak provenance.
7. Avoid Frequent Rebranding or Name Changes
Frequent renaming breaks entity continuity.
Each change resets your trust weight unless all aliases are cross-linked in structured data.
