India’s AI Ambition: Sovereignty or Permission to Customise?
India’s digital public infrastructure is the envy of the developing world. From the Unified Payments Interface (UPI) to the ambitious Bhashini project aiming to bridge the country’s linguistic divide, the narrative is one of self-reliance. The government explicitly frames its massive data center build-outs and local language initiatives as a triumph of "AI Sovereignty."
However, when viewed through the lens of Strategic Dependency Analysis framework developed by Neville Calvert of Calcorp Capital Resources, a different reality emerges. India is constructing a sophisticated ecosystem of "Sovereignty Theatre." It has successfully achieved data sovereignty and infrastructure ownership, but it has surrendered the only layer that truly matters: Model Sovereignty.
In the new AI economy, India is positioning itself not as a sovereign creator, but as a tenant operating on American architectural foundations.

The LLaMA Trap: Permission, Not Power
The cornerstone of India’s current AI strategy is the fine-tuning of open-weight models to preserve cultural context. Indigenous champions like Sarvam AI and AI4Bharat are doing commendable work building models tailored to India’s 22 official languages and thousands of dialects.
Yet, we must examine the foundation. These models are overwhelmingly built on Meta’s LLaMA architecture.
This distinction is critical. The base model—the neural architecture, the training weights, the fundamental understanding of logic—is American. The training approach is American. Indian developers are merely fine-tuning the outer layers. As I noted in my analysis of the global "Sovereignty Premium," this is not sovereignty; "it is permission to customise".
This creates an existential strategic dependency. Meta retains the power to update LLaMA, revise licensing terms, or restrict access at any time. India’s investment in culturally relevant AI sits entirely on a foundation controlled by a single American corporation. If the geopolitical winds shift, or if Meta alters its open-source strategy, India’s "sovereign" capabilities could be rendered obsolete overnight.

The Illusion of Infrastructure
To support this AI boom, India is overseeing a massive expansion of data center capacity, partnering with hyperscalers like Oracle, Amazon Web Services (AWS), and Google.
Policymakers point to these local data centers and strict data localization laws as proof of independence. This conflates geography with control.
India has achieved Data Sovereignty (the files remain within national borders) and Infrastructure Sovereignty (local companies or subsidiaries operate the buildings),. But it lacks Model Sovereignty. India has sovereignty over where the computing happens, but the United States and China have sovereignty over what the computing knows.
By inviting hyperscalers to build the physical infrastructure, India is effectively building "hosting infrastructure for American and Chinese AI platforms". The data centers are real, and the jobs are local, but the intelligence layer is imported.

The Scale Deficit
Why doesn't India simply build its own base models from scratch? The answer lies in the "Feasibility Threshold" of the AI era.
Training a frontier model requires an Integrated Stack of gigawatt-scale power, tens of thousands of synchronized GPUs, and capital expenditures exceeding $100 million per training run,. Currently, India’s entire GPU infrastructure cannot match what OpenAI deploys for a single training run.
Without this capacity, India is forced into the "Inference Trap." It builds infrastructure to use AI (Inference) rather than create it (Training). As I have argued repeatedly, "Training creates control; Inference creates dependency". By focusing on deployment rather than creation, India ensures it remains a downstream consumer of intelligence ground in Silicon Valley.

The Valuation Arbitrage
This dynamic creates a dangerous distortion in financial markets. Indian cloud infrastructure providers are currently receiving "AI valuations"—trading at technology multiples—despite operating what are essentially commercial real estate business models.
Investors are betting on "Indian AI," but they are buying exposure to companies that license American models and host American servers. These are property plays, not technology assets. If the underlying American platforms change their regional strategies, these "sovereign" assets face significant stranded asset risk.
The Strategic Reality: AI Sovereignty Is About Training Capability
Across the global AI landscape, three observations are empirically clear:
Observation 1 — Training Concentration Is Extreme
Public disclosures and industry estimates suggest:
Frontier training runs now cost $100M–$500M+ total lifecycle cost.
Leading labs deploy tens of thousands of GPUs per run.
Training cycles require multi-year capital continuity, not startup-style funding.
Observation 2 — Inference Infrastructure Is Commoditizing
Global trends show:
Cloud inference margins declining.
Model performance gaps shrinking between frontier and near-frontier models.
Distillation and synthetic data reducing training cost thresholds over time.
Observation 3 — Talent Follows Training Opportunity
Historically:
Semiconductor talent clustered around fabrication.
Aerospace talent clustered around launch programs.
AI research clusters around training-scale compute access.
Conclusion: Training capability density — not raw model size — is the most realistic sovereignty metric.
India’s Structural Strengths (Evidence-Based)
India starts from a stronger base than often assumed.
Digital Population Scale
1.4B population generating diverse multimodal data
Massive real-world language diversity unmatched globally
DPI datasets enable population-scale model evaluation
Software and Systems Talent
One of the largest global pools of distributed systems engineers
Strong cost-efficiency in large-scale software operations
Energy Expansion Trajectory
Among fastest-growing renewable capacity markets globally
Large potential for solar + storage coupling for training workloads
Strategic Neutrality Advantage
Ability to collaborate with both Western and non-Western tech ecosystems
The Five Pillars of Indian Tech Sovereignty
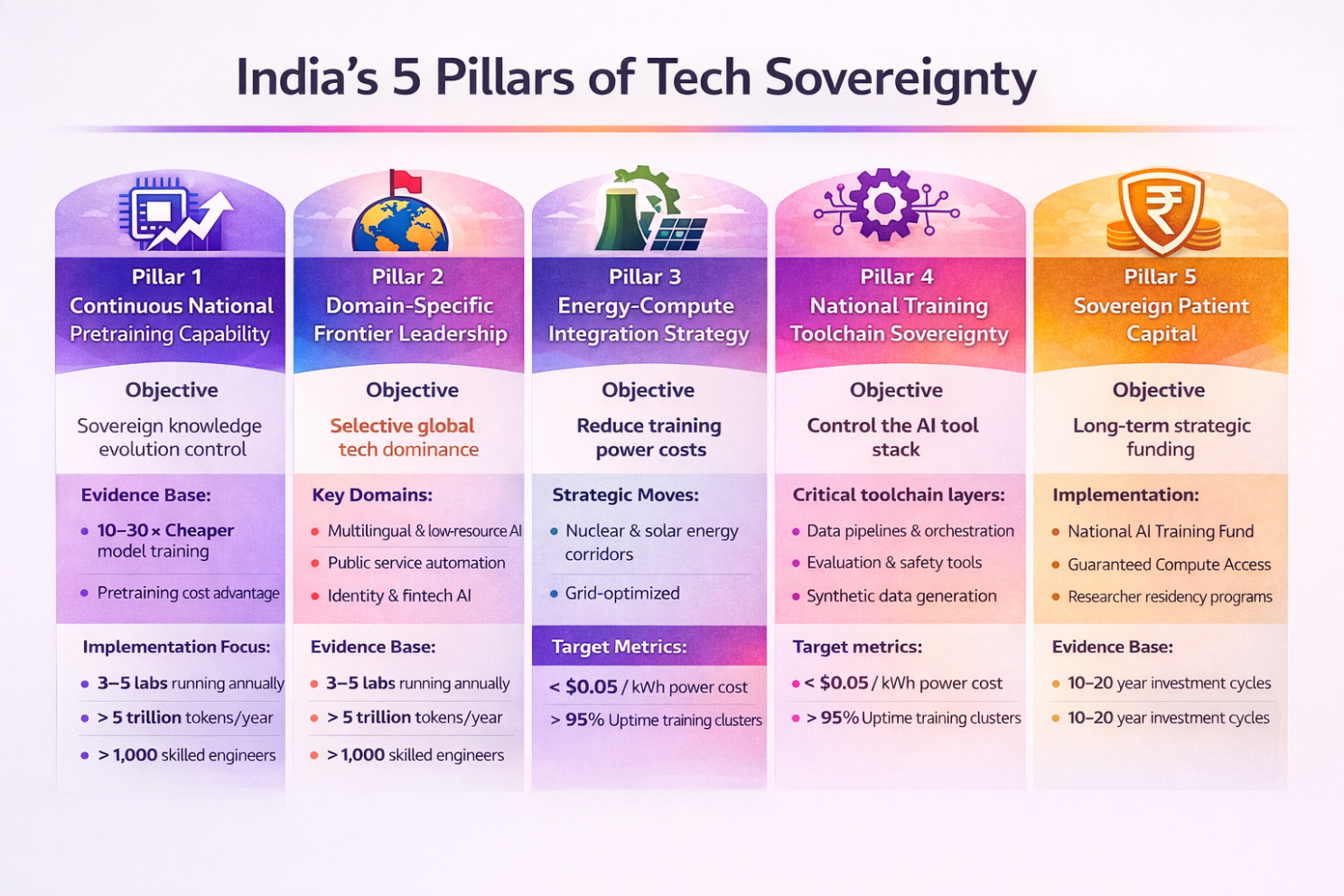
Pillar 1 — Continuous National Pretraining Capability
Objective
Move from fine-tuning dependency toward sovereign knowledge evolution control.
Evidence Base
Mid-scale model training costs are declining:
30B–70B class model training can be 10–30× cheaper than frontier runs.
Continued pretraining is significantly cheaper than training from scratch.
Implementation Focus
Build domestic capability in:
Large-scale token pipeline management
Distributed training orchestration
Evaluation and benchmarking frameworks
Target Metrics (5-Year Horizon)
3–5 domestic labs running annual large-scale training cycles
≥ 5 trillion tokens trained domestically per year
≥ 1,000 engineers with hands-on large training experience
Pillar 2 — Domain-Specific Frontier Leadership
Objective
Achieve selective global dominance, not general model parity.
Highest Probability Strategic Domains
Multilingual speech and translation
Low-resource language reasoning
Public service automation AI
Identity + fintech trust modeling
Population-scale education tutoring AI
Evidence Base
Historically, technology leadership often emerges through domain concentration:
Japan: precision manufacturing
Taiwan: semiconductor fabrication
Israel: cybersecurity and defense AI
Pillar 3 — Energy-Compute Integration Strategy
Objective
Lower long-term training cost per token.
Evidence Base
Training cost = Compute + Power + Cooling + Time + Talent.
Power cost is becoming dominant at scale.
Strategic Moves
Create AI Training Energy Corridors combining:
Nuclear baseload
Solar oversupply capture
Grid-priority compute zones
Target Metrics
Sub-$0.05 per kWh effective training power cost
Dedicated training clusters with >95% uptime power guarantees
Pillar 4 — National Training Toolchain Sovereignty
Objective
Control the process even when using foreign-origin architectures.
Critical Toolchain Layers
Data pipeline automation
Training orchestration frameworks
Evaluation and red-teaming stacks
Synthetic data generation pipelines
Alignment and RLHF tooling
Evidence Base
Toolchain ownership historically drives industry control (e.g., semiconductor EDA tools).
Pillar 5 — Sovereign Patient Capital
Objective
Replace venture-style funding with strategic capability funding.
Evidence Base
Frontier R&D cycles historically require:
10–20 year capital horizons
Guaranteed infrastructure access
Talent retention incentives
Implementation
National AI Training Fund
Guaranteed compute allocation programs
Long-term researcher residency incentives
10-Year Realistic Sovereignty Outcomes
If executed well, India could realistically achieve:
By ~2035:
Top 3 global multilingual model ecosystem
Self-sufficient mid-frontier training capability
Exportable sovereign AI stack for Global South markets
Reduced reliance on foreign model evolution cycles
Not full frontier parity — but real strategic autonomy.
Risks and Mitigations
Risk: Talent Migration
Mitigation:
Guarantee recurring training opportunities domestically
Offer compute access as talent retention mechanism
Risk: Capital Fragmentation
Mitigation:
Centralized training fund with multi-year mandates
Risk: Infrastructure Overinvestment Without Training Use
Mitigation:
Training utilization quotas for national compute clusters
Five-Year Action Plan (Pragmatic and Executable)
Year 1–2: Foundation Phase
Establish National AI Training Fund
Launch 2 national training clusters
Fund 3 domestic continued-pretraining programs
Year 3–4: Expansion Phase
Scale to 5+ active training labs
Launch domain-specific frontier model programs
Deploy national evaluation and benchmarking infrastructure
Year 5: Consolidation Phase
Export sovereign AI stack to partner nations
Establish recurring national training cycle cadence
Achieve domestic training self-sufficiency for mid-frontier models
Key National KPIs to Track
Instead of tracking only data centers or startups:
Track:
Tokens trained domestically per year
Cost per training token
Number of domestic large training runs
Training-capable engineering workforce size
% of compute used for training vs inference
Conclusion
India does not need to replicate U.S. or Chinese frontier AI ecosystems to achieve meaningful sovereignty. A more pragmatic and economically rational strategy is to build training capability density, dominate strategic AI domains, and integrate energy and compute policy.
Sovereignty in the AI era will not be binary. It will be measured in degrees of control over intelligence generation, evolution, and deployment. With disciplined execution, India can realistically move from downstream consumer to selective sovereign creator within a decade.
Legal Notice
Legal Notice Strategic Dependency Analysis™ is a trademark of Calcorp Capital Resources. The frameworks, methodologies, and concepts described in this article—including the "Training/Inference Split," the "Zombie Company" classification, and "Sovereignty Theatre"—are derived from the AI Infrastructure Dependency Series by Neville Calvert.
• Methodology Owner: Neville Calvert, Principal Advisor.
• Corporate Entity: Calcorp Capital.
• Source Material: AI Infrastructure Dependency Series.
• Key Proprietary Terms:
◦ Strategic Dependency Analysis (SDA).
◦ The Calcorp Dependency Monitor.
◦ Sovereignty Theatre.
◦ Reverse Acquihire.
◦ Zombie Companies.