The Minimum Viable Data Contract (MVDC): Architecting Data Quality and Governance for the AI-Native Enterprise
Executive Summary
The emergence of Artificial Intelligence (AI) and autonomous agentic systems is forcing telecommunications companies to confront a systemic challenge: data debt. This accumulation of fragmented, siloed, and inconsistent data is the top barrier preventing organizations from successfully implementing and scaling GenAI applications. Traditional data management architectures, built on rigid, legacy systems, cannot support the real-time, high-quality, trustworthy data required by modern AI models, leading to operational bottlenecks, unreliable predictions, and soaring costs.
This whitepaper argues that overcoming data debt requires a paradigm shift from reactive data cleansing to proactive data governance, anchored by modern data architectures and the Minimum Viable Data Contract (MVDC). The MVDC is a foundational principle of AI-native operations, establishing a formal, codified agreement between data producers and consumers that governs quality, schema, and semantics. By implementing MVDC frameworks, CSPs can transform data from a chaotic byproduct into a unifying strategic asset, ensuring that AI agents and production systems operate reliably, securely, and in compliance with regulatory mandates.


1. The Crisis of Data Debt and the AI Imperative
The core challenge facing telecommunications companies today is structural: legacy IT systems, often 20–30 years old, rely on monolithic architectures that were never designed to support real-time financial or AI services. This heritage results in "data debt" where enterprise value is trapped in sprawling, inconsistent data assets.
The impact is measurable:
• Wasted Time and Cost: Data teams spend an average of 62% of their time cleaning up data, leaving only 38% for meaningful analysis.
• Fragmented Decision-Making: Simple questions about customer metrics can take days to resolve because data is tracked differently across Customer Relationship Management (CRM), billing, and network operations systems.
• Impeded AI Scalability: A large majority of executives (72%) report struggling to implement and scale GenAI due cases due to this lack of fundamental data readiness.
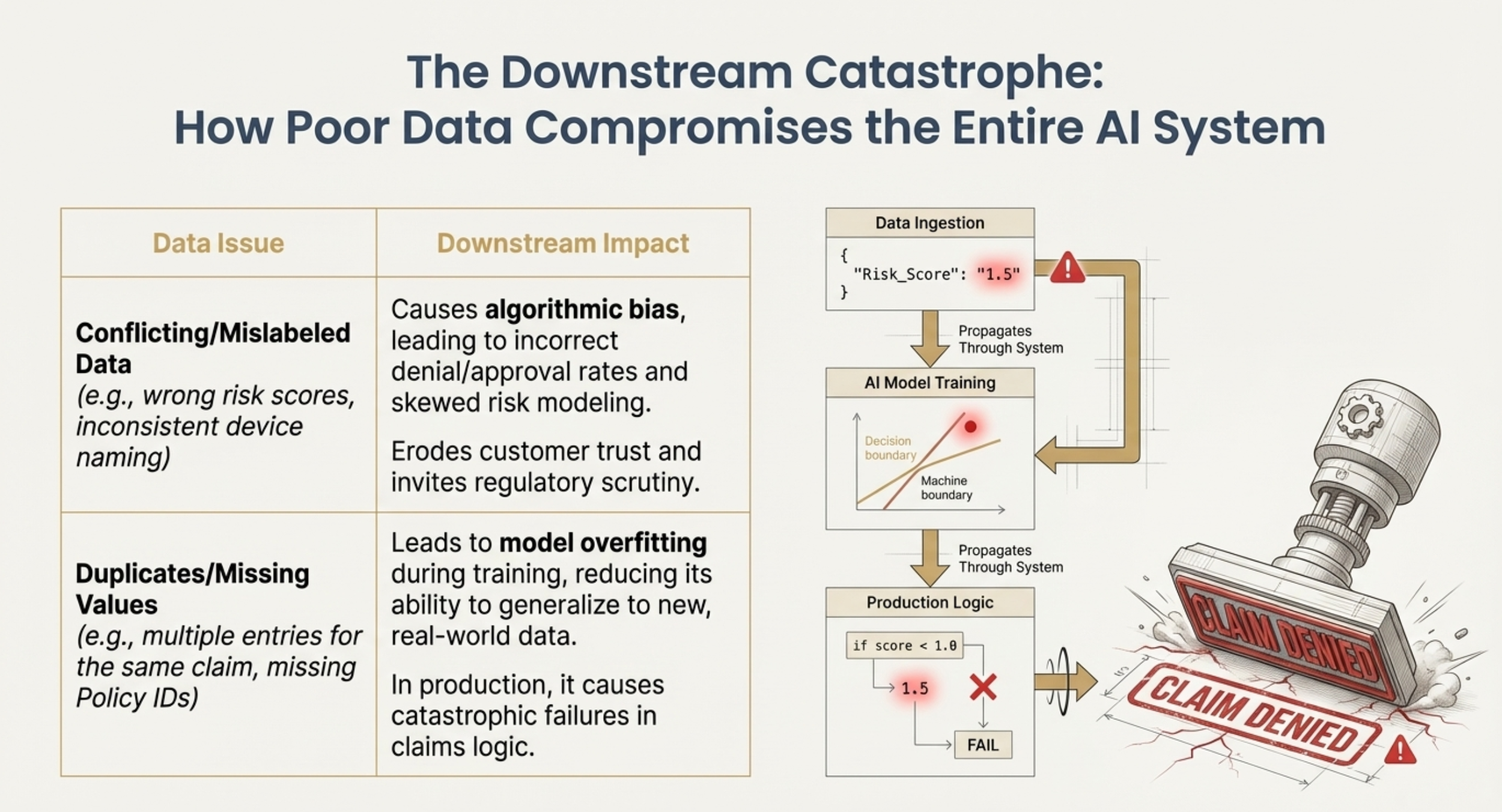
AI fundamentally elevates the stakes of this problem. For AI systems to function effectively and avoid critical failure modes, they require immense volumes of data characterized by high quality, relevance, and consistency.
• Hallucinations: AI models produce "hallucinations" (nonsensical or fabricated content) or misleading falsehoods when they lack factual, contextual data input.
• Bias and Discrimination: If the training data is poor, unstructured, or biased, the AI model can reinforce prejudices, leading to unfair outcomes in resource allocation or service interactions.
• Systemic Failure: In complex, multi-domain environments managed by AI agents, poor data quality directly compromises the reliability of automated decision-making across network optimization and fraud detection.
The urgency of achieving robust data quality is therefore a strategic prerequisite, moving from being an IT challenge to a foundational business imperative.
2. Reimagining Data Architecture for Quality
Traditional data management, typically reliant on segregated data warehouses and monolithic data lakes, has failed because these systems lack the flexibility and real-time capabilities necessary for modern AI deployment. To address this, leading organizations are adopting two complementary, AI-native architectural paradigms: Data Fabric and Data Mesh.
The Shift to Hybrid Data Architectures
• Data Fabric Architecture: This establishes an intelligent, unifying layer across disparate data sources (network, customer, operational systems). It minimizes friction by integrating capabilities such as cataloging, metadata management, and orchestration to create a cohesive, interoperable ecosystem. This framework ensures that data flows freely without requiring costly physical consolidation.
• Data Mesh Architecture: This decentralizes data ownership by treating data as an internal product managed by specialized domain teams (e.g., billing, networks, customer experience). Each domain team is accountable for the data's quality, security, and usability, ensuring that data meets centralized standards while enabling localized control.
A hybrid approach leverages the mesh model to decentralize ownership while using the fabric model as the connective tissue to integrate data sources and provide a unified metadata layer across the enterprise. This robust architecture is the first step toward enabling real-time insights and cross-functional coordination necessary for effective agentic systems.
Leveraging AI to Fix Data Debt
Crucially, the solutions to data debt lie within the very technology the data must serve. GenAI and machine learning (ML) can be applied as a "tech for tech" lever to remediate and streamline data management:
• Automated Reverse Engineering: LLMs can analyze undocumented or legacy code, database structures, and scripts to automatically map the sprawling data estate, quickly uncovering dependencies and accelerating modernization.
• Metadata Generation and Curation: AI assists in automatically generating detailed, high-quality metadata (e.g., creating column descriptions for 87,000 fields) and building unified knowledge graphs that map relationships across siloed datasets.
• Synthetic Data Generation: To fill gaps in datasets, address data imbalance (where critical events like network errors are underrepresented), or protect sensitive information, GenAI can generate synthetic data that mirrors actual operations and customer behaviors.
• Continuous Monitoring: Multi-agentic systems can be deployed to constantly monitor data quality, detect anomalies, and trigger real-time remedial actions, substantially increasing confidence in the data foundation.

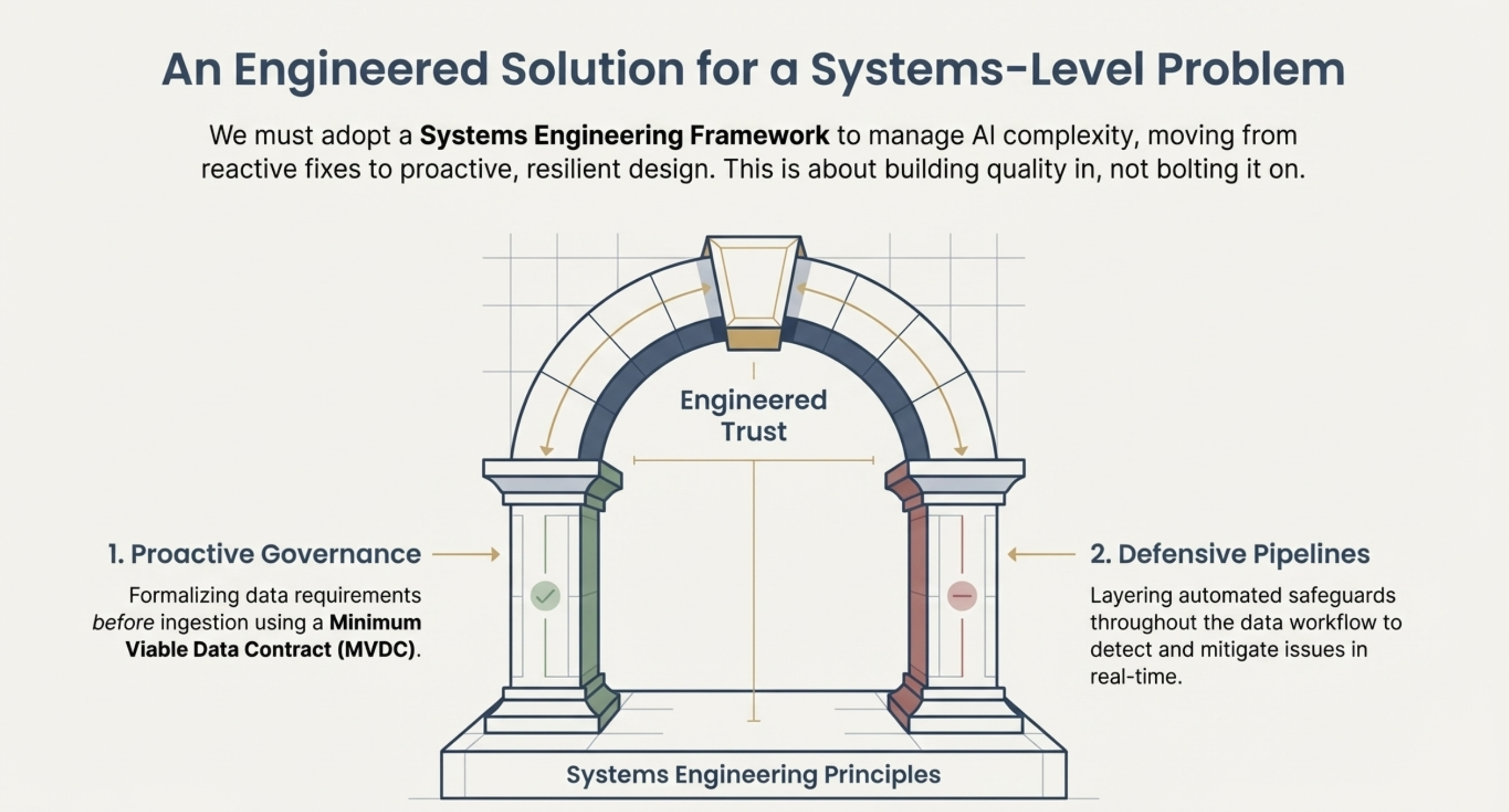
3. The Minimum Viable Data Contract (MVDC) Framework
While modern architecture provides the structural capacity and AI tools aid remediation, neither guarantees the consistency and reliability needed for production-grade, autonomous software. The necessary mechanism is the Minimum Viable Data Contract (MVDC).
Defining the Data Contract
The MVDC is a formal agreement between the system supplying the data (producer) and the application consuming it (consumer), clearly setting expectations for data structure and quality. It provides the governance and standardization essential for AI-driven pipelines.
An MVDC should explicitly define:
1. Schema and Semantics: The precise data structure, formats, data types, and the meaning of the data (semantics).

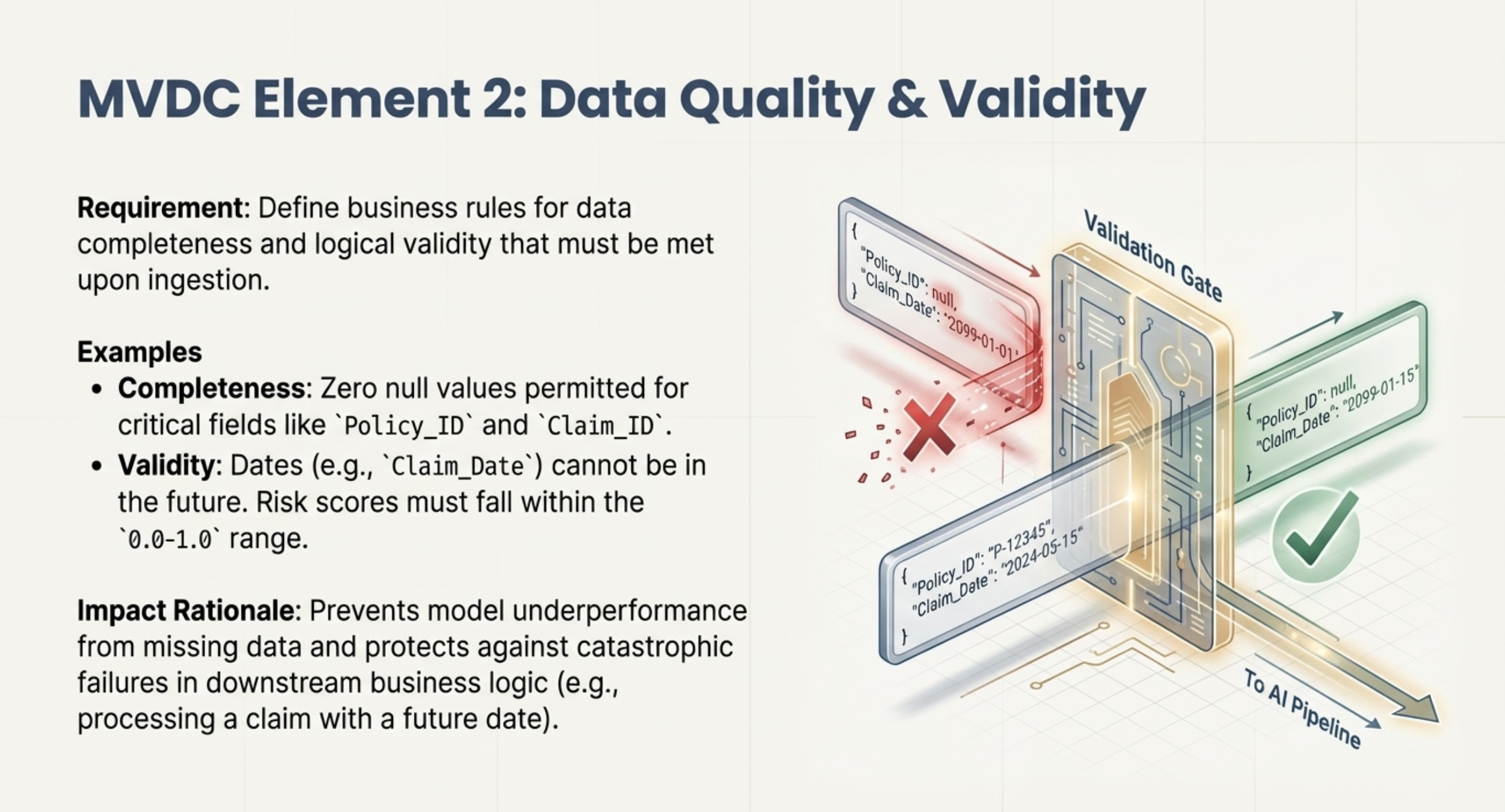
2. Quality Expectations: The minimum required level of accuracy, completeness, and consistency that the data must meet.
3. Auditability and Logging: Requirements for logging key events and decisions to ensure that every outcome can be traced back to the specific data or rule that generated it.
MVDC as the Guardrail for Autonomous Development
The MVDC framework is critical when considering the impact of vibe coding and the AI Software Factory. Vibe coding involves conversing with a Large Language Model (LLM) to generate code based on natural language inputs ("vibe"), which often results in complexity, technical debt, and security flaws because LLMs struggle to maintain logical consistency over long, iterative sessions.
The MVDC acts as the structured constraint mechanism necessary to address this inherent fragility.
• Formalizing Intent: MVDC converts vague human intent (vibe) into clear, unambiguous, machine-actionable specifications (Type III systems). This process, known as autoformalization, translates natural language goals into verifiable specifications (constraints) that the AI must adhere to.
• Enforcing Correctness: In an AI Factory pipeline, the MVDC allows the Quality & Safety Engine to enforce strict schemas and non-functional goals (such as performance or cost efficiency) on AI-generated code, fundamentally closing the gap between functionality and enterprise-grade reliability.
• Continuous Validation: MVDC specifications enable the continuous verification of AI-generated code against established constraints, detecting critical logic flaws, security vulnerabilities, and state-machine divergence at compile time.

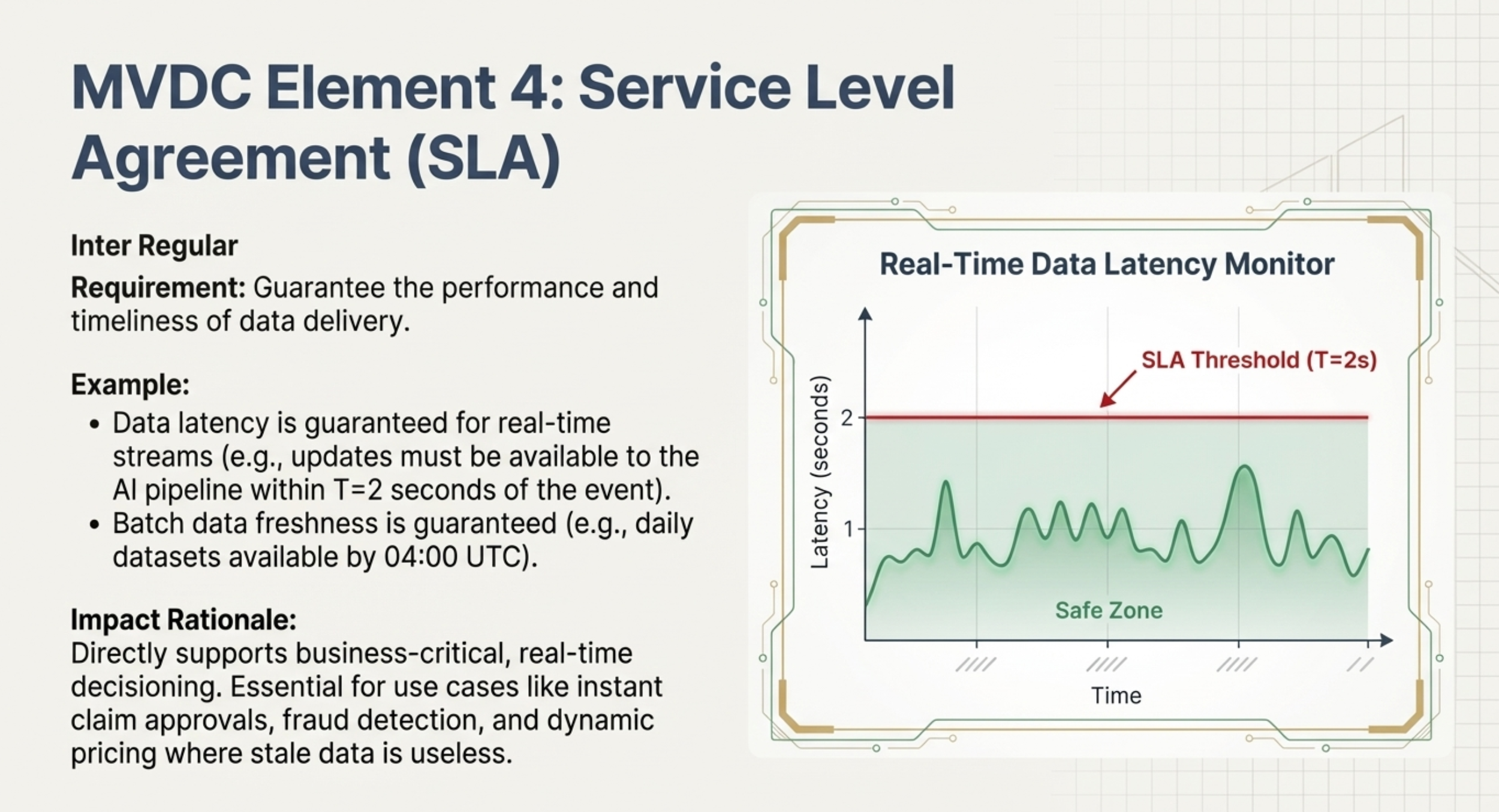
4. Service Level Agreements (SLAs): Commitments from the data producer regarding data freshness (latency) and availability.
4. MVDC in Practice: Ensuring Trust and Compliance
The implementation of MVDC and strong data governance practices directly addresses the most severe challenges related to AI security and regulatory compliance.
Protecting Sensitive Data and Preventing Breaches
Data privacy and security are paramount, especially as telcos handle highly sensitive information like location data and personally identifiable information (PII). Robust governance built on MVDC principles must ensure compliance with regulations such as GDPR and CCPA.
To achieve this, the MVDC framework integrates Privacy-Enhancing Technologies (PETs) into the data lifecycle:
• Differential Privacy: This technique adds noise to datasets to protect the source identifying features of individual data samples, enabling the MVDC to define data sharing requirements without compromising privacy.
• Federated Learning: Instead of moving raw data to a central location, the MVDC governs the process where copies of the AI algorithm are sent to local nodes (e.g., base stations) for training on local data, with only the aggregated model parameters being shared, ensuring data remains at its source.
• Data Masking/Tokenization: MVDC protocols specify the use of techniques like static masking and dynamic data masking to obfuscate sensitive PII and ensure that only anonymized or pseudonymized data is consumed by AI agents.
Auditing and Maintaining Trust
Accountability and transparency are non-negotiable for AI operating within critical infrastructure. The MVDC framework provides the necessary auditability:
• Traceability: MVDC mandates comprehensive logging and metadata tracking so that every decision, code change, or policy outcome implemented by an AI agent can be traced back to the original specifications and data sources.
• MVDC Lifecycle Management: The MVDC itself is a "living artifact" that requires continuous management. AI agents are deployed to constantly monitor datasets for drift detection (where data characteristics change over time) against the MVDC's expectations, triggering alerts and refinement processes when integrity degrades.



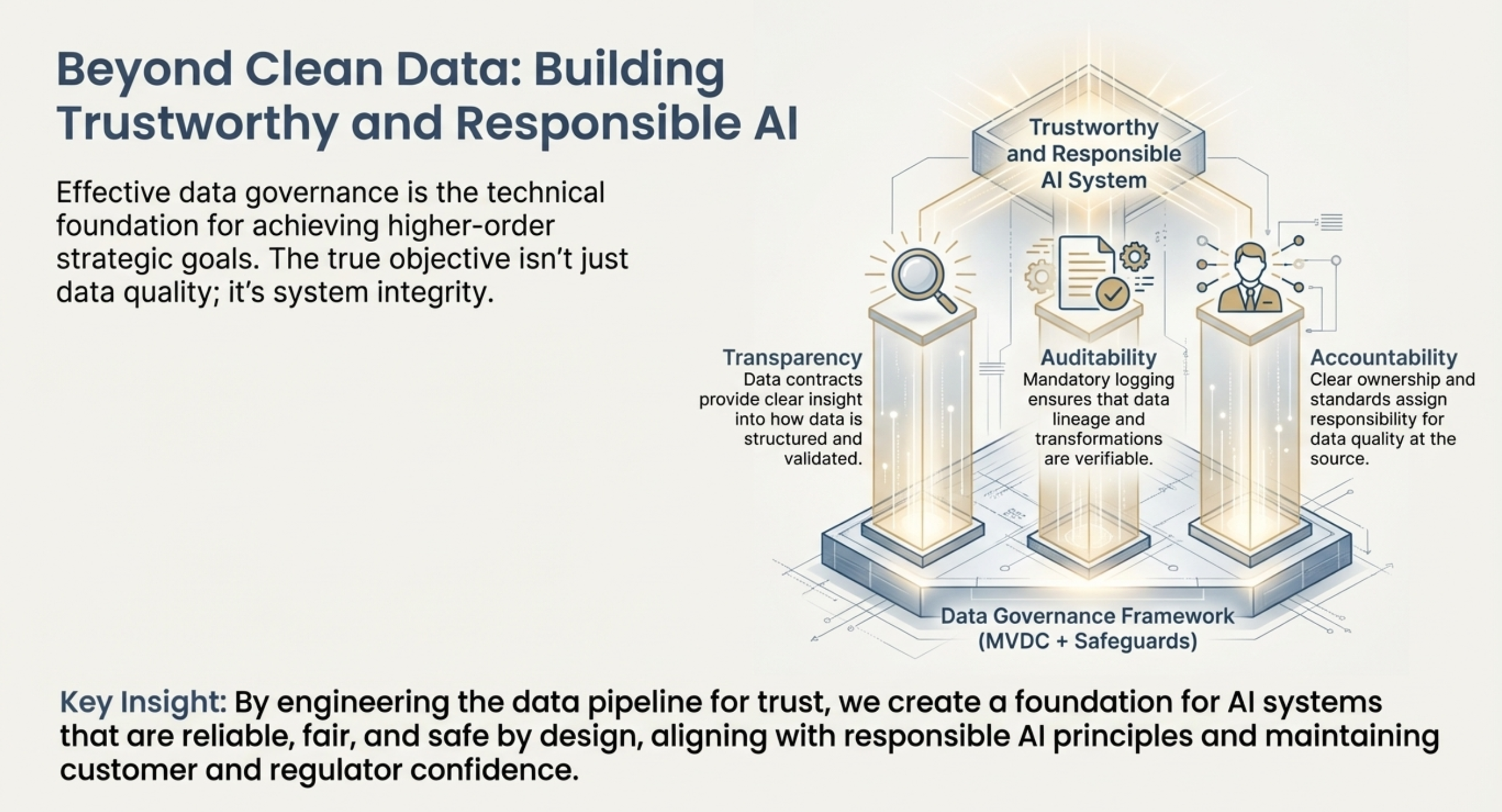
Conclusion
The future of the AI-native enterprise is predicated on mastering data quality and governance today. The Minimum Viable Data Contract (MVDC), enabled by modern data architectures (mesh and fabric) and accelerated by Generative AI tools, provides the strategic clarity and technical discipline required.
By embracing the MVDC, CSPs move beyond simply managing data debt to establishing a robust, transparent foundation where autonomous agents can thrive, enabling faster time-to-market for new services, reducing operational complexity, and ensuring sustainable competitive advantage in the age of AI. Failure to adopt this disciplined, data-first approach risks confining AI initiatives to isolated, unreliable experiments, leaving organizations exposed to increasing complexity and falling behind vertically integrated competitors. The time to codify the integrity of enterprise data is now.
